近日,自然语言处理国际顶级会议ACL2025录用结果出炉,禁漫天堂 自然语言处理团队和合作单位共有40篇论文被录用,其中主会论文23篇,Findings论文17篇。
ACL2025将于2025年7月27日-8月1日在奥地利维也纳举行,一年一度的ACL年会是自然语言处理领域最受关注的顶级学术会议之一,由国际计算语言学协会组织,在中国计算机学会(CCF)和中国人工智能学会(CAAI)推荐会议列表中被列为A类会议。
以下是录用论文的简要介绍(排名不分先后)。

论文标题:A3:AutomaticAlignmentFrameworkforAttributedTextGeneration
论文作者:YueWang*,HaokeZhang*,JuntaoLi#,JinxiongChang,MinZhang
发表会议:ACL2025Main
简介:可溯源文本生成通过为回复中的每个陈述提供引用,提高大语言模型生成内容的可靠性,从而使用户能够轻松验证回答是否正确。然而,由于缺乏高质量的训练数据,当前的可溯源生成系统在对齐陈述和引用上存在很大提升空间。并且,现有的大模型指令遵循对齐方法,容易误导大模型过度关注无关文档,从而降低回答质量。为此,我们提出了一套新颖的可溯源文本生成自动对齐框架(A3),能够在无需人工标注的前提下,自动生成高质量的带引用问答对用于监督微调和偏好优化。在A3的帮助下,Mistral-7B在ASQA数据集上达到了84.4%的引用召回率和87.0%的精确率,显著超越了GPT-4在同一任务上73.0%的召回率和76.5%的精确率。
论文标题:ATraining-freeLLM-basedApproachtoGeneralChineseCharacterErrorCorrection
论文作者:HouquanZhou,BoZhang,ZhenghuaLi#,MingYan,MinZhang
发表会议:ACL2025Main
合作单位:阿里通义
项目地址://github.com/Jacob-Zhou/simple-csc
论文链接://arxiv.org/abs/2502.15266
简介:汉语拼写纠错(Chinesespellingcorrection,CSC)任务旨在纠正汉语文本中的错别字,具有巨大实用价值的任务。传统的CSC任务主要关注字符替换错误,而另外两种常见的字级别错误,即缺字错误和多字错误,则较少受到关注。这些错误在标注过程中常常被排除在CSC数据集之外。即使在评估过程中已被标注也会在模型评测时被忽略。这一问题限制了CSC任务的实用性。为解决此问题,我们引入了广义汉语字级别错误纠正(GeneralChineseCharacterErrorCorrection,C2EC)任务。该任务包含字替换、非连续的字插入和非连续的字删除,这三类错误。我们通过合并并人工校验来自CCTC和Lemon数据集的数据,构建了一个高质量的C2EC基准数据集。我们将免训练、免提示词的CSC方法扩展到C2EC,通过使用编辑距离(Levenshteindistance)处理文本长度变化,并利用一个额外的基于提示词的大语言模型(LLM)来进一步提升性能。实验表明,我们的方法无需任何微调,即可使一个14B参数的LLM在传统的CSC任务和C2EC任务上,达到与参数量近50倍的大模型(DeepSeekV3)相媲美的性能。
论文标题:AccurateKVCacheQuantizationwithOutlierTokensTracing
作者:YiSu*,YuechiZhou*,QuantongQiu,JuntaoLi#,QingrongXia,PingLi,XinyuDuan,ZhefengWang,MinZhang
发表会议:ACL2025Main
合作单位:华为云
简介:大语言模型(LLM)的强大能力w是以部署期间大量计算资源为代价的。虽然KVCache可以显著减少推理过程中的重新计算,但它也会引入额外的内存开销。KVCache量化提供了一种有前景的解决方案,在内存使用和准确性之间取得了良好的平衡。先前的研究表明,Key是按照Channel分布的,而Value是按照Token分布的。因此,常见的做法是对Key应用Channel-wise量化,对Value应用Token-wise量化。然而,我们的进一步调查表明,一小部分不寻常的令牌表现出偏离这种模式的独特特征,这可能会对量化精度产生重大影响。为了解决这个问题,我们开发了一种简单而有效的方法,在解码过程中准确识别这些令牌,并将其作为异常令牌排除在量化之外,从而显著提高了整体准确性。大量实验表明,我们的方法在2-bit量化下实现了显著的精度提高,可以将内存使用量减少6.4倍,吞吐量增加2.3

论文标题:AnEmpiricalStudyofIterativeRefinementsforNon-autoregressiveTranslation
论文作者:YishengXiao,PeiGuo,ZechenSun,JuntaoLi#,KaiSong,MinZhang
发表会议:ACL2025Main
简介:迭代非自回归模型具有混合自回归和完全非自回归模型的精神,寻求生成质量和推理效率之间的平衡。这些模型最近在各种生成任务中表现出了令人印象深刻的性能,超过了自回归模型。然而,它们也面临着阻碍进一步发展的若干挑战。在这项工作中,我们的目标是构建更高效、更具竞争力的迭代非自回归模型。具体而言,该论文回顾了各种迭代非自回归模型,以此找到实现我们目标的关键因素。同时提出了一种简单而有效的评分策略,可以在不降低生成质量的情况下进一步提升生成效率。该技术对于提升当前生成式大语言模型的生成效率具备很大潜力,能够支持改变传统自回归式的生成方案,提供探索新型解码策略的有效方案。
论文标题:BasicReadingDistillation
论文作者:ZhiZhou,SiruiMiao,XiangyuDuan#,HaoYang,MinZhang
发表会议:ACL2025Main
简介:蒸馏通过知识蒸馏或任务蒸馏将大模型蒸馏为小模型,这两种方法虽训练小模型模仿大模型的某些特定特征,却都忽视了对小模型进行与各下游任务无关的基础阅读教育。本文提出基础阅读蒸馏(BRD),教导小模型模仿大模型在每个普通句子上的基础阅读行为(如命名实体识别、提问与回答),以实现基础教育。这类似于我们的模型经过了中学/大学的阅读教育后,再进行各个下游任务的测试,而不是像现有方法仅消耗token进行训练后直接暴露于测试环境。在经过这种基础教育后,我们将小模型应用于包括语言推理基准和BIG-bench任务在内的多种任务。结果显示小模型可以超越或达到比其大20倍以上的大模型的性能水平。分析表明,BRD能有效影响小模型的概率分布,并与知识蒸馏或任务蒸馏具有正交性。
论文标题:Decoder-OnlyLLMscanbeMaskedAuto-Encoders
论文作者:DanQiao,YuanGao,ZhemingYang,DiYang,ZihengWu,PengchengLu,MinghuiQiu,JuntaoLi#,MinZhang
发表会议:ACL2025Main
合作单位:字节跳动
简介:现代自然语言处理工作系统(如RAG)需要针对生成任务和表征任务使用不同的模型,其中双向预训练编码器(Bi-Encoder)和解码器大型语言模型(Decoder-Only-LLM)分别主导表征任务和生成任务。模型之间的结构差异会导致额外的开发成本,并限制任务之间的知识共享。在该工作中,我们提出了UniMAE,这是一种全新的无监督训练方法,可将解Decoder-OnlyLLM转换为单向掩码自编码器(UniMAE)。UniMAE在保留LLM生成能力的同时,将高质量语义信息压缩到[EOS]token的embedding中。在56个MTEB数据集上的综合评测结果表明,UniMAE仅需100步训练即可在无监督设置下取得SOTA的结果,首次在Decoder-Only架构上建立了统一生成学习与表示学习的训练方法。

论文标题:DISC:Plug-and-PlayDecodingInterventionwithSimilarityofCharactersforChineseSpellingCheck
论文作者:ZihengQiao,HouquanZhou,YumengLiu,ZhenghuaLi#,MinZhang,BoZhang,ChenLi,JiZhang,FeiHuang
合作单位:阿里通义
发表会议:ACL2025Main
论文链接://arxiv.org/abs/2412.12863
简介:在汉语拼写纠错(CSC)任务中,汉字混淆集(同音近音近形字符集合)主要有两种利用方式:训练时建模字符间的相似关系(数据增强、GCN);预测时约束解码空间,提高精确率。然而,针对后一方式,混淆集不包含字符间具体相似度,实际使用性能极度依赖混淆集和数据集的适配性。我们提出一套拼音和字形相似度的计算策略,并根据具体的相似度值干预模型的预测。整个过程都是无需训练且即插即用的,适配几乎所有主流CSC模型。多个基准的实验证明,我们的方法能够稳定提升现有模型的纠错性能。
论文标题:DynamicHeadSelectionforNeuralLexicalizedConstituencyParsing
论文作者:YangHou,ZhenghuaLi#
发表会议:ACL2025Main
简介:词汇化句法分析通过关联成分节点与词汇中心词,连接了短语结构和依存结构。随着神经网络的发展,词汇化结构逐渐被非词汇化的基于跨度的方法所取代。在本文中,我们重新审视词汇化句法分析,并提出了一种新颖的潜在词汇化方法,该方法在训练过程中动态推断中心词,无需依赖预定义的中心词识别规则。我们的方法使模型能够直接从数据中学习词汇间的依存关系,从而在不同语言和数据集上具有更强的适应能力。我们在多个树库上的实验证明了该方法达到或接近当前最先进的性能。同时,我们还分析了模型学习到的依存结构、中心词偏好以及语言偏见。
论文标题:EmployingDiscourseCoherenceEnhancementtoImproveCross-DocumentEventandEntityCoreferenceResolution
论文作者:XinyuChen,PeifengLi#,QiaomingZhu
发表会议:ACL2025Main
简介:跨文档同指消解(CDCR)旨在识别并归类分散在多个文档中对特定事件或实体。与文档级任务不同的是,在文档级任务中,事件和实体可以通过丰富连贯的上下文进行关联,跨文档场景缺乏这种关键的上下文,这为建立它们之间的联系带来了重大挑战。针对这一问题,我们提出了一个新任务"跨文档篇章连贯性增强"(CD-DCE),旨在加强两个跨文档事件或实体实例之间的篇章连贯性。具体而言,CD-DCE首先筛选出具有连贯性的文本,然后将其插入两个跨文档实例之间,形成一个新的连贯文本。随后,这些连贯文本被用来表征事件或实体,并进行同指消解。在三个常用数据集上的实验结果表明,我们提出的方法优于多个最先进的基准模型。该方法为处理跨文档信息关联提供了新的技术思路,在新闻分析、司法案例关联等领域具有重要应用价值。
论文标题:EnhancingGoal-orientedProactiveDialogueSystemsviaConsistencyReflectionandCorrection
论文作者:DidiZhang*,YaxinFan*,PeifengLi#,QiaomingZhu
发表会议:ACL2025Main
简介:目标导向的主动对话系统旨在通过规划一条目标导向的对话路径,引导用户对话自然地朝特定的目标推进。然而,现有研究主要聚焦于优化路径规划,忽视了生成回复与对话上下文(包括用户画像、对话历史、领域知识以及子目标)之间可能存在的不一致问题。为了解决这一问题,我们提出了一种与模型无关的两阶段“一致性反思与纠正”(ConsistencyReflectionandCorrection,CRC)框架。具体而言,在一致性反思阶段,模型被引导对生成回复与对话上下文之间的差异进行反思,识别不一致之处并提出可能的修正建议;在一致性校正阶段,模型基于反思结果生成与对话上下文更为一致的回复。我们在多种参数规模的模型架构上进行了实验,涵盖编码器-解码器架构(如BART、T5)以及仅解码器架构(如GPT-2、DialoGPT、Phi3、Mistral和LLaMA3)。在三个数据集上的实验结果表明,CRC框架能显著提升生成回复与对话上下文之间的一致性。
论文标题:GenerativeRewardModelingviaSyntheticCriteriaPreferenceLearning
论文作者:Xiaoboliang,HaokeZhang,JuntaoLi#,KehaiChen,QiaomingZhu,MinZhang
发表会议:ACL2025Main
简介:在OpenAI研究科学家姚顺雨《TheSecondHalf》的观点中,他指出研究重点正从单纯的模型能力转向“任务定义+好的评估标准”这一关键组合。尤其在真实世界中,评估往往是多维度的、细粒度的,不仅难以统一标准,还常常伴随高昂的代价和极差的可扩展性。为破解这一核心瓶颈,本文提出了SyncPL,一种全新的生成式奖励建模框架。SyncPL将评估过程结构化为一棵“偏好树”,以层次化方式表示评估维度之间的关系与依赖,并通过inference-timescaling与预定义的奖励规则进行优化,使模型不仅能为每个查询合成不同评价标准,还能对它们的重要性进行排序与理解。更进一步,本文还提出了结合o1-like长链思维策略的变体SyncPL-o1,通过引入可扩展的长推理路径,有效降低训练成本、增强评估稳定性,在多个复杂基准任务中实现了优异性能。

论文标题:ImprovingDialogueDiscourseParsingthroughDiscourse-awareUtteranceClarification
论文作者:YaxinFan,PeifengLi#,QiaomingZhu
发表会议:ACL2025Main
简介:对话篇章解析旨在分析对话中篇章单元之间的修辞关系。然而,对话中常见的省略、俚语等语言现象经常引发歧义,给解析器识别篇章关系带来巨大挑战。为此,我们提出一种篇章感知的消歧模块(DCM),通过为篇章解析器提供消歧后的篇章单元来增强其性能。DCM通过两种推理过程协同工作:消歧类型推理负责解析语言特征以确定澄清类型,篇章目标推理则指导篇章单元的消歧过程,使其更倾向于真实关系而远离歧义关系。进一步地,我们提出贡献感知的偏好优化(CPO)机制来降低错误澄清带来的级联误差风险。该机制使解析器能够评估DCM提供消歧篇章单元的的贡献度,进而给DCM提供反馈来优化DCM与解析器的协同效果。在对话篇章解析数据集上的实验结果表明,我们的方法通过有效解决篇章单元歧义问题,显著提升了对话篇章解析器的性能。
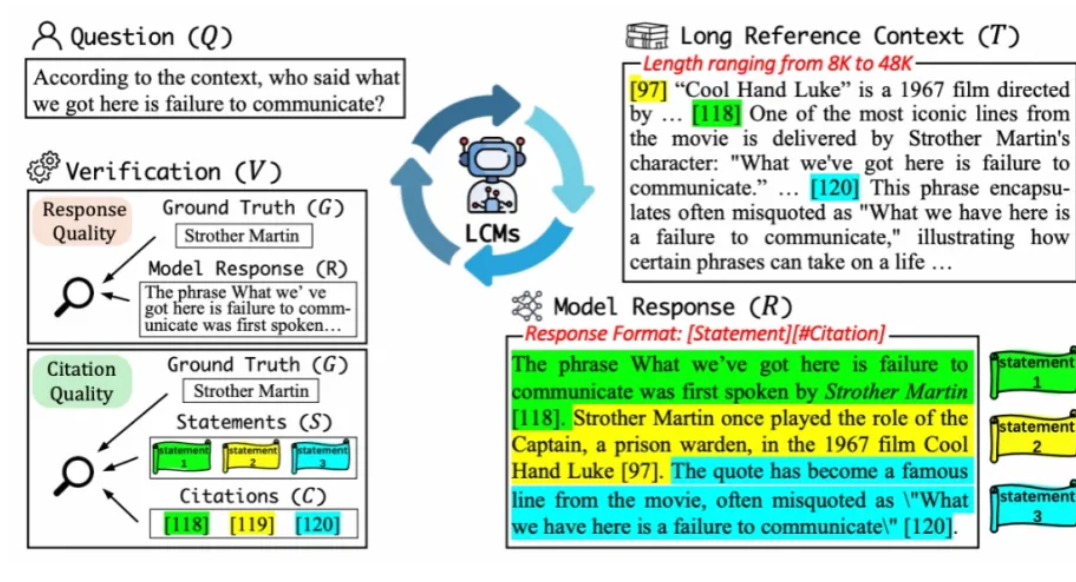
论文标题:L-CiteEval:ASuiteforEvaluatingFidelityofLong-contextModels
论文作者:ZechengTang*,KeyanZhou*,JuntaoLi#,BaibeiJi,JianyeHou,MinZhang
发表会议:ACL2025Main
项目地址://github.com/ZetangForward/L-CITEEVAL
Huggingface://huggingface.co/datasets/Jonaszky123/L-CiteEval
简介:近年来,长上下文模型(LCMs)取得了显著进展,推动了长文档问答等实际任务的发展。这类模型的成功通常基于一个假设:它们能够充分理解并利用长上下文,而非仅依赖预训练中获得的知识。然而,我们发现开源LCMs在忠实性方面表现不如预期。为此,我们提出了一个开箱即用的评估工具集,覆盖11项任务(上下文长度从8K到48K),可全面评估LCMs在长上下文任务中的生成质量与忠实性,并配有自动化评估流程。我们对11个主流开源与闭源LCMs的评测显示:尽管它们在生成质量上的差距较小,开源模型在忠实性方面仍明显落后。此外,我们还从显式生成输出和模型内部注意力机制两个角度,分析了引用生成对提升LCMs表现的作用。
论文标题:MixtureofSmallandLargeModelsforChineseSpellingCheck
论文作者:ZihengQiao,HouquanZhou,ZhenghuaLi#
发表会议:ACL2025Main
简介:大模型拥有稳定输出正确流畅语句的能力,这与汉语拼写纠错任务目标天生适配,然而,现有大模型方法面临着过度纠正不可控、微调所需资源大以及in-domain数据集上综合纠错性能不如小模型的问题。对于BERT-based小模型来说,序列标注的建模方式更贴合汉语拼写纠错任务输入输出等长的特点。它微调方便、性能高,但是偶尔会因过拟合到某一特定编辑对而生成错误字符。两类模型呈现互补特点。因此,我们设计了一种大小模型协同纠错方法,同时使用大小模型进行预测过程,将小模型的概率分布对齐到每个大模型token上,在beamsearch解码过程中合并了大小模型的概率。实验证明,在众多基准中,我们的大小模型协同方法能够稳定且显著地提升现有模型的SOTA性能,充分实现大小模型相辅相成的效果。
论文标题:MultimodalCoreferenceResolutionforChineseSocialMediaDialogues:DatasetandBenchmarkApproach
论文作者:XingyuLi,ChenGong#,GuohongFu
发表会议:ACL2025Main
论文链接://arxiv.org/abs/2504.14321
简介:随着社交媒体多模态内容的日益丰富,多模态指代消解(MCR)在理解用户交互、关联图文信息方面至关重要。然而,真实场景下的多模态指代消解研究仍面临数据匮乏的挑战。为此,本文提出了首个中文社交媒体多模态指代消解数据集TikTalkCoref,该数据集基于抖音短视频平台构建,共包含1012个短视频和评论对话,2,179个指称以及1,435条共指链。本文还提出了一种专注于名人领域的多模态指代消解基准方法,并在TikTalkCoref数据集上进行了广泛实验,验证了该方法的有效性,为该领域提供了可靠的基准测试结果。
论文标题:QuASAR:AQuestion-DrivenStructure-AwareApproachforTable-to-TextGeneration
论文作者:WeiJieLiu,YibinZheng,FangKong#
发表会议:ACL2025Main
简介:表格到文本生成任务旨在从结构化或半结构化的表格数据中自动生成自然语言描述。与传统的文本生成任务不同,该任务要求模型能够准确理解并表达表格的结构信息。现有方法通常通过将表格线性化或转换为图结构来进行建模。然而,这些方法要么无法充分捕捉表格的结构特性,要么依赖复杂的注意力机制,因而在实际应用中存在一定的局限性。为了解决上述问题,我们提出了一种名为QuASAR的方法,该方法基于问题驱动的自监督学习框架,旨在提升模型对表格结构的感知与表征能力。具体而言,QuASAR构造了一组结构相关的问题,用于自监督训练,从而显式引导模型捕捉局部与全局的结构信息。此外,我们还引入了两个辅助预训练任务:稀疏到稠密的文本转换任务,以及数值内容的摘要任务,以进一步提升生成文本的质量与连贯性。在ToTTo和HiTab两个数据集上的实验结果表明,QuASAR相较现有方法能够生成更高质量的文本描述。
论文标题:Table-Critic:AMulti-AgentFrameworkforCollaborativeCriticismandRefinementinTableReasoning
论文作者:PeiyingYu,GuoxinChen,JingjingWang
发表会议:ACL2025Main
合作单位:中科院计算所
论文链接://arxiv.org/abs/2502.11799
代码链接://github.com/Peiying-Yu/Table-Critic
简介:在处理表格推理任务时,大型语言模型(LLMs)往往难以在多步推理过程中保持一致性,且现有方法缺乏有效的中间错误识别与纠正机制,容易导致错误传播。为此,论文提出了Table-Critic框架,该框架借助多智能体协作与自进化模板树,系统地解决了表格推理中的错误识别与迭代优化问题。Table-Critic包含四个智能体:Judge负责定位推理步骤中的具体错误类型,并通过自进化模板树路由匹配的批评模板;Critic依据模板对首个错误步骤进行详细分析,生成改进建议;Refiner基于批评意见重构推理链,避免受历史错误影响;Curator在推理链验证正确后,从优化过程中提取新的批评模板,通过垂直或水平扩展更新模板树结构,实现批评知识的持续积累。实验结果显示,Table-Critic显著优于现有分解方法和基于批评的推理模型。其多轮优化机制在5次迭代内即可收敛。消融实验表明,自进化模板树机制对性能提升至关重要,动态适应能力使模型能有效处理新型错误。Table-Critic为表格推理提供了一种鲁棒的多智能体协作范式,其自进化知识积累机制为复杂推理任务中的错误管理提供了新方向,展现了在文本与多模态推理场景中的扩展潜力。
论文标题:TwoIntermediateTranslationsAreBetterThanOne:Fine-tuningLLMsforDocument-levelTranslationRefinement
论文作者:YichenDong,XinglinLyu,JunhuiLi#,DaimengWei,MinZhang,ShiminTao,HaoYang
发表会议:ACL2025Main
合作单位:华为文本机器翻译实验室
论文链接://arxiv.org/abs/2504.05614
简介:大语言模型(LLM)能够通过自我修复提升翻译质量。本文在此基础上,将翻译修复范围从句子级扩展到篇章级,重点关注篇章到篇章(Doc2Doc)的翻译修复过程。由于句子到句子(Sent2Sent)和篇章到篇章翻译分别针对翻译过程的不同层面,我们提出通过两种中间翻译结果对LLM进行微调,结合Sent2Sent与Doc2Doc的优势进行翻译修复。此外,针对中间翻译质量存在差异的特点,我们引入了一种具有质量感知的增强微调方法——该方法为简单翻译分配较低权重,为复杂翻译分配较高权重,使模型能够聚焦于具有挑战性的翻译样例。基于LLaMA-3-8B-Instruct和Mistral-Nemo-Instruct模型在十个语向中的实验结果表明,该方法的有效性得到充分验证。
论文标题:UniICL:AnEfficientICLFrameworkUnifyingCompression,Selection,andGeneration
论文作者:JunGao,QiLv,ZiliWang,TianxiangWu,ZiqiangCao#,WenjieLi
发表会议:ACL2025Main
论文链接://arxiv.org/pdf/2405.17062
简介:现有大模型(LLMs)的上下文学习(ICL)依赖示例拼接,但面临输入长度激增和浅层示例选择的瓶颈。为此,我们提出UniICL框架,通过可学习的"记忆槽"将示例压缩为稠密向量(12倍压缩率),并基于语义相似度动态筛选最相关示例,同时构建"示例银行"缓存压缩结果以避免重复计算。广泛的领域外实验证明了UniICL的效果与效率。
论文标题:UnleashingLLMReasoningCapabilityviaScalableQuestionSynthesisfromScratch
论文作者:YuyangDing,XinyuShi,xiaoboliang,JuntaoLi#,ZhaopengTu,QiaomingZhu,MinZhang
发表会议:ACL2025Main
合作单位:腾讯AILab
项目地址://scalequest.github.io
简介:提升大语言模型(LLMs)的数学推理能力是推动人工智能发展的关键。然而获取大规模、多样化且高质量的推理数据集仍是开源社区面临的重大挑战。为此,我们提出ScaleQuest,一种新颖、可扩展的数据合成方法,引入了两阶段的问题调优流程,包括问题微调(QFT)与问题偏好优化(QPO),有效激发模型的问题生成潜力。实验结果表明,使用我们数据训练的模型在领域内与跨领域评估中优于现有开源数据集;随训练数据量增加持续提升,模型的性能持续增长。

论文标题:UsingSubtexttoEnhanceGenerativeIDRR
论文作者:ZhipangWang,YuHong#,WeihaoSunandGuodongZhou
发表会议:ACL2025Main
简介:该文针对隐式篇章关系(IDRR)开展研究。针对的科学问题是,语言往往存在潜台词,并且这类潜台词是构成语义关系的真正内在线索,对于识别隐式关系能够提供重要依据。本文的主要贡献在于,提出基于大语言模型的论元潜台词生成方法,以及利用潜台词识别结果加强论元语义表示,从而提升隐式关系的识别精度。实验利用PDTB2.0和3.0两个版本对所提方法进行了论证,集中在以Decoder-only为基座的IDRR模型上进行性能对比。实验结果显示,利用潜台词优化语义表示和隐式关系识别的方法,能够有效提高IDRR的F1性能,并在对比具有同类型基座的前沿方法中,取得了具有竞争力的性能。
论文标题:RevisitingClassicalChineseEventExtractionwithAncientLiterature
Information
论文作者:XiaoyiBao,ZhongqingWang#,JinghangGuandChu-RenHuang
发表会议:ACL2025Main
简介:关于古文事件抽取的研究往往直接借鉴英文或现代中文的复杂建模方法,而忽略了该语言独特特性的利用。该文认为,与其从其他语言中移植复杂的方法,不如专注于古文独特的“古代文献”来源,这能够为事件抽取提供额外且全面的语义信息。基于此动机,该文提出了一种用于古文事件抽取的LiteraryVision-LanguageModel,该模型结合了文献注释、历史背景和文字字形信息,从序列中捕捉内在与外在的上下文信息。大量实验表明,LVLM的方法在GuwenEE和CHED数据集上达到了新的最先进性能,这不仅验证了该文提出的VLM的有效性,更重要的是,这些独特特性几乎可以以零成本精确获取。

论文标题:AComprehensiveGraphFrameworkforQuestionAnsweringwithMode-SeekingPreferenceAlignment
论文作者:QuanweiTang,SophiaYatMeiLee,JunshuangWu,DongZhang#,ShoushanLi,ErikCambria,GuodongZhou
发表会议:ACL2025Findings
简介:尽管大型语言模型(LLM)在知识密集型任务中表现出色,但是面对训练时没有见过的问题仍面临挑战。检索增强生成(RAG)方法通过整合外部知识,提升了模型的回答能力和泛化性能。然而,在实现全局理解以及使回答符合人类道德和质量偏好方面,现有方法仍然存在局限性。为此,我们提出了GraphMPA,一种基于图的综合框架,并集成了模式搜索偏好对齐机制。具体而言,我们使用通用的相似性度量方法构建了一个层次化的文档图,模拟人类理解和综合信息的认知过程。此外,我们还引入了模式搜索偏好优化策略,通过概率匹配约束使模型输出与人类偏好更好地对齐。在六个数据集上进行的广泛实验证明了我们的方法的有效性和广泛适用性。

论文标题:ALW:AdaptiveLayer-WisecontrastivedecodingenhancingreasoningabilityinLargeLanguageModels
论文作者:YuechiZhou,ChuyueZhou,JianxinZhang,JuntaoLi#,MinZhang
发表会议:ACL2025Findings
简介:大型语言模型在各种推理任务表现出色,但对于参数较少或预训练数据不足的LLM仍存在挑战。通过实验,我们发现跨层的噪声积累通常会导致推理过程中的词元预测不稳定,而对比跨层的概率分布可以有效地减轻这种干扰。基于此,我们提出了自适应层间对比解码,通过动态地将浅层中的噪声与深层中的关键信号分离来增强推理能力。在多个推理基准测试中进行的大量实验表明,在保持推理效率的同时,该方法持续提高了多个大语言模型的推理答案准确率。

论文标题:CapturingNuancedPreferences:Preference-AlignedDistillationforSmallLanguageModels
论文作者:YangganGu,JunzhuoLi,SiruiHuang,XinZou,ZhenghuaLi#,XumingHu#
发表会议:ACL2025Findings
合作单位:香港科技大学(广州)NLPGroup
简介:教师大模型对于不同的回复序列有偏好倾向,但以往工作中将其建模为简单的二元信号,忽略了教师模型对于回复的细粒度信息。我们提出了一种新颖的偏好蒸馏框架Preference-AlignedDistillation(PAD),尝试用概率分布的形式来建模细粒度的偏好倾向,并蒸馏到学生小模型上,以缓解现有大模型蒸馏方法对偏好信息建模不足的问题。在4个主流benchmarks上的结果显示,我们的方法优于传统的知识蒸馏方法和主流的偏好蒸馏方法。以Gemma-2B-it为学生模型时,经过PAD训练的模型在Arena-Hard上达到了20%的提升,验证了该方法在偏好对齐上的有效性。
论文标题:EvaluatingLLMs'FactualKnowledgeUtilizationonUnanswerableQuestions
论文作者:ChuanyuanTan,WenbiaoShao,HaoXiong,TongZhu,ZhenhuaLiu,KaiShi,WenliangChen#
发表会议:ACL2025Findings
简介:处理不可回答问题(UAQ)对于大语言模型(LLM)至关重要,因为这有助于LLM在复杂情况下给出误导性回复。尽管之前的研究已经构建了多个数据集来评估LLM在UAQ上的表现,这些数据集缺乏事实知识支持,这限制了评估LLM在处理UAQ时利用事实知识的能力。为弥补这一缺陷,我们构建了一个新的不可回答问题数据集FactUAQ,这是一个结合知识图谱创建的带有辅助事实知识的中英双语数据集,含有3种类型的UAQ:空交集、时间和伪选项。基于FactUAQ,我们进一步定义了两个新任务,分别衡量LLM利用内部和外部事实知识的能力。我们在多个LLM系列上的实验结果表明,FactUAQ对目前的LLM而言具有挑战,因为即使LLM已经掌握了事实知识,其表现依然欠佳。此外,我们发现结合外部知识可能会提高性能,但LLM仍然无法充分利用这些外部知识,导致回复错误。
论文标题:ExploringKnowledgeFilteringforRetrieval-AugmentedDiscriminativeTasks
论文作者:MinjieQiang,ZhongqingWang#,XiaoyiBao,HaoYuanMa,ShoushanLi,GuodongZhou
发表会议:ACL2025Findings
简介:基于检索增强的方法在缓解大语言模型幻觉问题上取得了显著进展。然而,引入外部知识并不总能带来预期的模型性能提升,因为检索到的知识中可能包含无关或有害的信息,从而影响预测过程的准确性。为了解决这些挑战,该文提出了一种新颖的框架,通过引入知识过滤和预测融合机制来提升模型性能。具体而言,该文首先采用基于困惑度的标注方法来收集训练数据。然后,设计了四种不同的策略来过滤有害的检索知识。最后,通过批量预测的方式将过滤后的知识整合生成最终结果。该文在多个判别任务数据集上进行了大量实验,以评估所提出框架的效果。结果表明,该框架能够显著提升模型在判别任务上的性能。
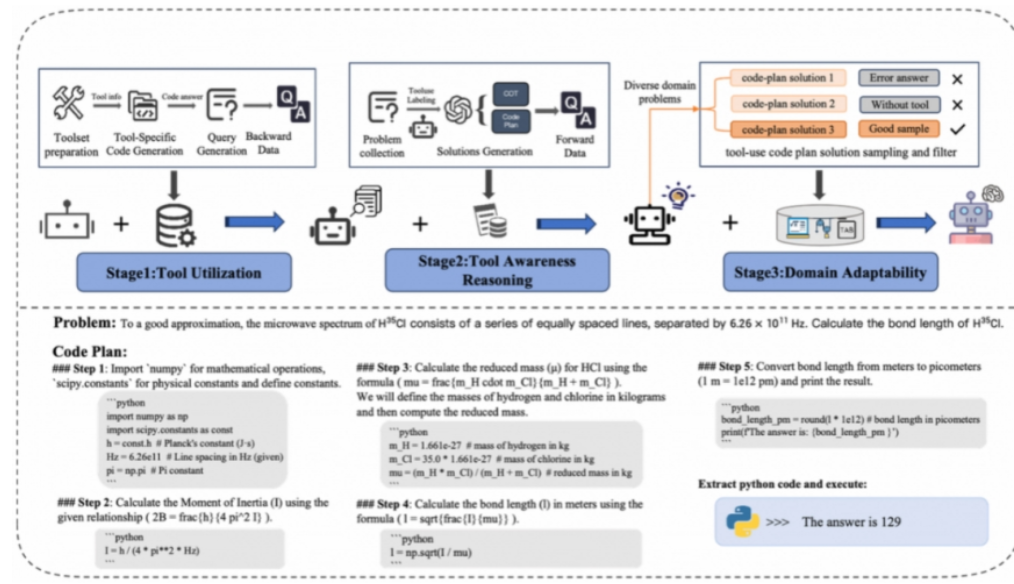
论文标题:FromAwarenesstoAdaptability:EnhancingToolUtilizationforReasoning
论文作者:WenjingXie,xiaoboliang,JuntaoLi#,WanfuWang,KehaiChen,QiaomingZhu,MinZhang
发表会议:ACL2025Findings
简介:为提升大语言模型(LLMs)在科学推理中的工具使用能力,我们提出了一种三阶段的训练方法——Tool-AwarenessTraining(TAT)。该方法结合前向与反向数据生成策略,强化模型对工具的理解与选择性使用。具体包括:通过反向生成数据构建工具知识;结合多步推理任务提升工具意识;利用大规模多任务领域数据提升模型的适应性。TAT有效融合了工具使用与科学推理能力,在多个数学与科学任务中显著提升了模型的工具使用主动性与执行成功率。
论文标题:Multi-HopQuestionGenerationviaDual-PerspectiveKeywordGuidance
论文作者:MaodongLi,LongyinZhang,FangKong#
发表会议:ACL2025Findings
简介:多跳问题生成(Multi-hopQuestionGeneration,MQG)是自然语言处理(NLP)中的一项基础任务,在自动问答、阅读理解等相关领域具有巨大应用潜力。MQG旨在生成需要综合文档中多个信息片段才能得出答案的问题,其主要挑战在于如何有效识别与问答对(Question-Answerpair)相关的关键信息片段,这一过程通常依赖于关键词。然而,现有研究未能充分发挥关键词的引导作用,同时忽视了问题关键词与文档关键词在任务中的不同功能角色。为了解决这一问题,我们引入了“双视角关键词”(Dual-perspectiveKeyword)——即问题关键词(QuestionKeyword)与文档关键词(DocumentKeyword),并提出了Dual-PerspectiveKeyword-Guided(DPKG)框架,将关键词无缝整合进多跳问题生成过程。我们认为,问题关键词用于捕捉提问者的意图,而文档关键词则反映与问答对相关的文档内容。在功能上,问题关键词与文档关键词协同作用,共同确定文档中的关键信息片段,并要求问题关键词必须出现在生成的问题中。我们系统分析了问题关键词、文档关键词及双视角关键词的引导作用,展示了DPKG在该任务中的出色表现,并强调了其在MQG任务中的重要价值。
论文标题:M3FinMeeting:AMultilingual,Multi-Sector,andMulti-TaskFinancialMeetingUnderstandingEvaluationDataset
论文作者:JieZhu,JunhuiLi#,YalongWen,XiandongLi,LifanGuo,FengChen
合作单位:阿里云通义点金、南京大学
发表会议:ACL2025Findings
项目地址://github.com/aliyun/qwen-dianjin
简介:近年来,大型语言模型(LLMs)的快速发展推动了金融领域评估基准的不断演进。然而,现有基准多依赖新闻、财报或公告,难以真实反映金融会议中的语言特点与交流动态。为此,我们提出了M3FinMeeting,一个多语言、多行业、多任务的数据集,专注于金融会议理解。M3FinMeeting具有三大特点:支持英语、中文和日语,覆盖由全球行业分类标准(GICS)定义的多个行业领域,并设有三项任务:摘要生成、问答对抽取与问答任务,从而实现更全面的模型评估。在七个主流LLMs上的实验结果表明,即使是最先进的长上下文模型,在金融会议理解方面仍存在明显不足,验证了M3FinMeeting作为评估基准的有效性与挑战性。
论文标题:One-DimensionalObjectDetectionforStreamingTextSegmentationofMeetingDialogue
论文作者:RuiHe,ZhongqingWang#,MinjieQiang,HonglingWang,YifanZhang,HuaXu,ShuaiFan,GuodongZhou
发表会议:ACL2025Findings
简介:对话文本分段旨在根据主题或逻辑将对话内容划分为连续的段落,从而提升其可读性和可管理性。当前的文本分段模型直接应用于STS(StreamingTextSegmentation,流式文本分段)时,存在诸多局限性,例如标签分布的不平衡影响模型训练的稳定性,以及模型训练任务(句子分类)与实际文本分段任务之间的差异限制了模型的分段能力。为了解决这些问题,该文首次通过滑动窗口分段方法实现了STS。其次,提出了两种不同层次的基于滑动窗口的平衡标签策略,以稳定流式分段模型的训练过程并加快训练收敛速度。最后,通过在窗口内对文本序列添加一维边界框回归任务,重构了STS任务的训练方法,将训练目标从句子分类转变为序列分段,从而使训练目标与任务目标保持一致,进一步提升了模型性能。本工作合作单位为:思必驰科技股份有限公司。
论文标题:RevealingandMitigatingtheLocalPatternShortcutsofMamba
论文作者:WangJieYou*,ZechengTang*,JuntaoLi#,LiliYao,MinZhang
发表会议:ACL2025Findings
简介:Mamba是一种基于状态空间模型(SSMs)的先进模型,具备线性复杂度和恒定内存需求。尽管据报道Mamba在性能上可与基于注意力的模型相媲美甚至超越,然而我们的分析发现两者之间存在性能差距:Mamba在涉及局部关键信息的任务中表现优异,但在需要处理分散关键信息的任务中面临挑战。我们的对照实验表明,这种不一致性源于Mamba在不同模型规模(10M到1.4B)上对局部模式捷径的依赖,这使得Mamba能够在其有限内存内记住局部关键信息,但妨碍了其保留更分散信息的能力。为此,我们在Mamba模型中引入了全局门控模块以解决该问题。在大量合成任务及真实任务中的实验结果表明,我们的方法是有效的。值得注意的是,尽管仅引入了4M额外参数,我们的方法便使Mamba模型(130M)在处理分布式信息的任务上取得了显著提升,其性能从不到5%提升到80%。

论文标题:Self-DenoisingMonteCarloAnnotationforRobustProcessRewardLearning
论文作者:YuyangDing,XinyuShi,JuntaoLi#,xiaoboliang,ZhaopengTu,MinZhang
发表会议:ACL2025Findings
合作单位:腾讯AILab
简介:过程奖励模型通过对模型推理过程中的每一步进行细粒度评估,在提升大语言模型(LLMs)复杂任务表现(如数学推理)方面展现出显著效果。然而,PRMs的构建依赖于人工标注数据,这不仅成本高昂,而且难以扩展。尽管基于蒙特卡洛(MonteCarlo,MC)估计生成的合成数据是一种有前景的替代方案,但其存在较高的噪声比例,容易导致模型过拟合,从而限制了大规模训练的效果。本研究对合成数据中的噪声分布进行了系统性的分析,并提出了一种高效的数据合成与抗噪声学习框架。该方法仅利用轻量级模型和极低的训练代价,合成数据的质量超过专家标注数据。

论文标题:SentimentalImageGenerationforAspect-basedSentimentAnalysis
论文作者:XiaoyiBao,JinghangGu,ZhongqingWang#andChu-RenHuang
发表会议:ACL2025Findings
简介:近年来,关于纯文本属性级情感分析(Aspect-BasedSentimentAnalysis,ABSA)的研究取得了令人瞩目的成果。然而,一个持续的挑战在于从原始数据中提取的语义信息有限。为了解决这一问题,研究人员尝试通过额外数据增强来改进纯文本ABSA。他们或者基于输入数据生成音频、文本和语言学特征,或者依赖用户发布的图像。然而,这些方法各有局限:前面提到的三种增强形式与原始数据高度重叠,这削弱了它们作为补充信息的能力;而用户发布的图像则极度依赖人工标注,这不仅将应用范围局限于少数的文本-图像数据集,还会将人工错误传播到整个下游任务环节中。该文探索了一种从未有人尝试过的生成情感图像的新方法,并提出了一种新颖的情感图像生成方法(SentimentalImageGeneration),能够精准地提供辅助的视觉语义来加强文本信息抽取。大量实验表明,该方法在ACOS、ASQP和en-Phone数据集上达到了新的SOTA(最先进)性能,验证了方法的有效性,并揭示了扩展ABSA特征的一个具有前景的方向。

论文标题:Span-basedSemanticRoleLabelingasLexicalizedConstituencyTreeParsing
论文作者:YangHou,ZhenghuaLi#
发表会议:ACL2025Findings
简介:语义角色标注(SemanticRoleLabeling,SRL)旨在识别句子中的谓词-论元结构。基于跨度的SRL是一种主流范式,通常采用基于BIO标注或图结构的方法来实现。然而,这些方法往往难以有效捕捉句法与语义之间的内在联系。尽管已有一些考虑句法信息的模型被提出以缓解这一问题,它们普遍依赖于现有的句法资源,从而限制了模型的通用性。在本研究中,我们提出了一种用于基于跨度SRL的词汇化树表示方法,该方法融合了短语结构和依存结构以显式建模谓词-论元结构。通过将谓词转化为树的根节点,并将论元表示为直接连接到谓词的子树,我们的方法有效地弥合了句法与语义表示之间的鸿沟。在标准基准数据集(CoNLL05和CoNLL12)上的实验结果表明,我们的模型在多项评估设定中取得了具有竞争力的性能,尤其在给定谓词的设定下表现出显著提升。
论文标题:ToollearningviaInference-timeScalingandCycleVerifier
论文作者:Xiaoboliang,WenjingXie,JuntaoLi#,WanfuWang,YibinChen,KehaiChen,MinZhang
发表会议:ACL2025Findings
简介:在现实世界中,工具千变万化、使用规则复杂,要让大模型“内化”每一个工具的使用方式几乎不可能。工具是大模型认知外界的关键接口,如何高效使用工具,正成为衡量大模型智能程度的核心指标。为此,我们提出了InfCycle,一个全新设计的工具使用学习框架,它无需手工标注示例,仅依赖于工具使用列表,即可自动建构高质量的训练数据,覆盖从单工具调用到多轮、多工具协同的广泛应用场景。InfCycle引入了循环式数据合成与验证机制,通过inference-timescaling和一致性验证不断优化数据质量,训练过程更高效、推理表现更稳健。即便仅使用7B模型,InfCycle在StableToolBench上也取得了75.4%的passrate和79.6%的winrate,充分展现了其在真实工具使用任务中的强大泛化能力。

论文标题:UnlockingRecursiveThinkingofLLMs:AlignmentviaRefinement
论文作者:HaokeZhang*,XiaoboLiang*,CunxiangWang,JuntaoLi#,MinZhang
发表会议:ACL2025Findings
项目地址://github.com/Banner-Z/ASCENT
简介:OpenAIo1等模型证明了长思维链对模型性能的巨大帮助。然而,当前大部分模型依旧无法进行这种有效的递归思考,尤其是在没有蒸馏数据的场景下。为此,我们提出了ASCENT框架,充分挖掘语言模型在长思维链中进行迭代式自我润色的潜力。具体而言,我们用一个评估动作和一个修改动作组成一次润色,结合差分学习技术最大化模型的润色奖励,这种奖励关注于润色前后的累计效果提升,而不是直接最大化模型润色结果。实验结果表明,我们的方法在效率和性能上均优于传统的偏好优化方法,仅使用约3000条合成数据,就可以让8B模型在对话任务中的胜率提高20%以上。

论文标题:Vision-aidedUnsupervisedConstituencyParsingwithMulti-MLLMDebating
论文作者:DongZhang,HaiyanTian,QingyingSun,ShoushanLi#
发表会议:ACL2025Findings
简介:本文聚焦于视觉辅助的无监督成分句法分析中所面临的跨模态对齐成本较高和忽视模型互补性的问题。针对这些问题,本文通过预训练模型热启动与多智能体协作机制,构建了一种双模型交互架构,并创新性地设计了共识驱动与轮次驱动两种辩论模式,以实现模型间的协同优化。实验结果表明,该框架在图像-文本与视频-文本数据集上均表现出色,通过模型间的多轮交互,不仅显著提升了句法解析结果的准确性,还增强了模型的跨领域适应能力。
